
Data engineering adalah salah satu cabang dari big data yang penuh dengan tantangan sekaligus peluang. Untuk bisa meniti karier sebagai data engineer, kamu butuh pengalaman nyata yang bisa mengasah keterampilan sekaligus membuktikan kemampuanmu. Salah satu cara terbaik adalah dengan mengerjakan contoh portofolio data engineering project sebagai bentuk latihan sekaligus bekal menuju karier profesional.
Bagi perusahaan, kandidat yang punya portofolio data engineering project biasanya lebih dilirik karena terlihat terampil dan mampu menghadirkan solusi nyata. Buat kamu yang masih pemula, project–project ini bisa jadi jalan cepat untuk menguasai skill, meningkatkan value di mata perekrut, dan tentu saja menambah amunisi saat melamar kerja.
Masih bingung harus mulai dari mana? Tenang, ada banyak ide project mulai dari yang sederhana hingga kompleks yang bisa kamu jadikan portofolio sekaligus media belajar. Yuk, simak daftarnya di artikel ini!
BACA JUGA: Ini 4 Tanda Utama Kamu Harus Career Switch
Kenapa Kamu Harus Membuat Portofolio Data Engineering Project?

Sebelum benar-benar terjun ke dunia kerja, portofolio adalah jembatan antara teori yang kamu pelajari dengan praktik nyata. Tanpa portofolio, keterampilanmu sulit diukur, dan perekrut pun tidak punya gambaran jelas tentang kemampuanmu. Selain itu, inilah alasan mengapa portofolio data engineering project sangat penting:
- Bukti Konkret Keterampilan
Sertifikat atau CV hanya bisa menunjukkan klaim. Namun, melalui portofolio, kamu bisa memberikan bukti nyata tentang bagaimana kamu membangun pipeline, mengolah data, hingga menghasilkan output yang siap digunakan. Inilah yang akan membedakanmu dari kandidat lain.
- Media Untuk Mengukur Kemampuan Diri
Setiap project yang kamu kerjakan akan menjadi cermin untuk menilai sejauh mana pemahamanmu terhadap konsep data engineering. Dari sini, kamu bisa menemukan area mana yang sudah kuat dan bagian mana yang masih perlu ditingkatkan.
- Agar Lebih Percaya Diri Saat Interview
Dengan portofolio, kamu tidak lagi hanya menjawab pertanyaan perekrut dengan teori. Kamu bisa menunjukkan hasil pekerjaan secara langsung baik dalam bentuk kode, arsitektur pipeline, maupun dashboard. Hal ini akan meningkatkan kepercayaan diri sekaligus kredibilitas kamu.
- Media Belajar yang Lebih Efektif
Proses membangun portofolio memaksamu menghadapi masalah nyata, seperti data tidak terstruktur, error pada pipeline, atau keterbatasan performa. Tantangan-tantangan inilah yang justru membuatmu belajar lebih cepat dan siap menghadapi situasi di dunia kerja.
- Nilai Tambah di Mata Perekrut
Bagi perusahaan, kandidat dengan portofolio selalu lebih menarik. Portofolio membuktikan bahwa kamu bukan hanya “paham teori”, tetapi juga mampu menghasilkan solusi nyata. Nilai tambah ini bisa menjadi faktor penentu saat bersaing dengan kandidat lain.
- Investasi untuk Personal Branding
Portofolio yang dipublikasikan di GitHub atau LinkedIn bukan hanya menjadi dokumentasi hasil kerja, tetapi juga membangun citra profesional. Semakin banyak project yang relevan kamu tampilkan, semakin besar peluangmu untuk dikenal sebagai calon data engineer yang kompeten.
BACA JUGA: 20+ Pertanyaan Interview Kerja yang Sering Muncul dan Cara Menjawabnya
Apa Saja Skill yang Dibutuhkan untuk Mengerjakan Portofolio Project Data Engineering?

Setelah memahami pentingnya portofolio, langkah berikutnya adalah memastikan kamu memiliki skill yang diperlukan untuk mengerjakannya. Tanpa fondasi yang tepat, project data engineering bisa terasa rumit dan sulit diselesaikan. Berikut adalah beberapa skill utama yang wajib kamu kuasai:
- Dasar Pemrograman
Bahasa pemrograman seperti Python atau Java banyak digunakan dalam data engineering. Python, misalnya, populer karena memiliki library kuat untuk manipulasi data dan otomatisasi pipeline.
- Penguasaan SQL dan Database
Hampir semua project data engineering melibatkan SQL. Kamu perlu terbiasa menulis query, mengelola database relasional, serta memahami konsep indexing dan optimasi agar proses pengambilan data lebih efisien.
- Konsep ETL (Extract, Transform, Load)
ETL adalah inti dari pekerjaan data engineer. Kamu harus memahami cara mengekstrak data dari berbagai sumber, membersihkannya, lalu memuatnya ke dalam sistem penyimpanan seperti data warehouse.
- Cloud Computing dan Big Data Tools
Platform seperti AWS, Google Cloud, atau Azure semakin banyak digunakan perusahaan. Selain itu, tools big data seperti Apache Spark atau Hadoop juga penting untuk memproses data dalam skala besar.
- Workflow Orchestration
Agar pipeline berjalan otomatis dan terjadwal, kamu perlu mengenal tools orkestrasi seperti Apache Airflow atau Prefect. Skill ini membantumu mengatur alur kerja project dengan lebih rapi dan terkontrol.
- Data Warehousing
Memahami konsep data warehouse seperti Redshift, Snowflake, atau BigQuery)akan membantumu merancang sistem penyimpanan yang terstruktur dan siap digunakan untuk analisis.
- Version Control dan Kolaborasi
Menguasai Git bukan hanya untuk menyimpan kode, tetapi juga untuk bekerja kolaboratif dalam tim. Ini adalah skill penting yang menunjukkan kamu siap terlibat dalam project nyata.
BACA JUGA: 10 Karakteristik Big Data Serta Contoh dan Manfaatnya
7 Contoh Portofolio Data Engineering Project

Setelah menguasai skill dasar, saatnya mengaplikasikannya melalui proyek nyata. Portofolio inilah yang nantinya akan menjadi bukti kemampuanmu di mata perekrut. Berikut beberapa ide contoh portofolio data engineering project yang bisa kamu kerjakan:
- Perform Data Modeling untuk Streaming Platform
Salah satu ide untuk bereksperimen melalui project data engineering adalah mempraktikkan data modeling. Pada project ini, kamu akan menganalisis preferensi pengguna untuk meningkatkan kinerja recommendation system pada berbagai streaming platform. Data modeling dapat mendukung penjelasan data kepada pengguna secara jelas dan spesifik.
Kamu perlu membuat ETL pipeline dengan Python dan PostgreSQL. Data modeling mengacu pada pengembangan diagram secara komprehensif dan menampilkan hubungan antara titik data yang berbeda. Beberapa poin data modeling yang dapat kamu tangani, yaitu:
- Album dan lagu yang disukai pengguna
- Playlist yang masuk ke dalam user library
- Genre yang paling sering didengarkan
- Lama pengguna mendengarkan serangkaian lagu tertentu dan timestamp yang bersangkutan
Informasi di atas dapat membantu kamu dalam melaksanakan kinerja data modeling dengan benar. Selain itu, muncul berbagai solusi praktis dan efektif dalam memecahkan masalah pada masing-masing platform. Penyelesaian project dapat membantu memberikan pengalaman dalam menangani ETL pipeline dan PostgreSQL.
- Membuat Data Lake
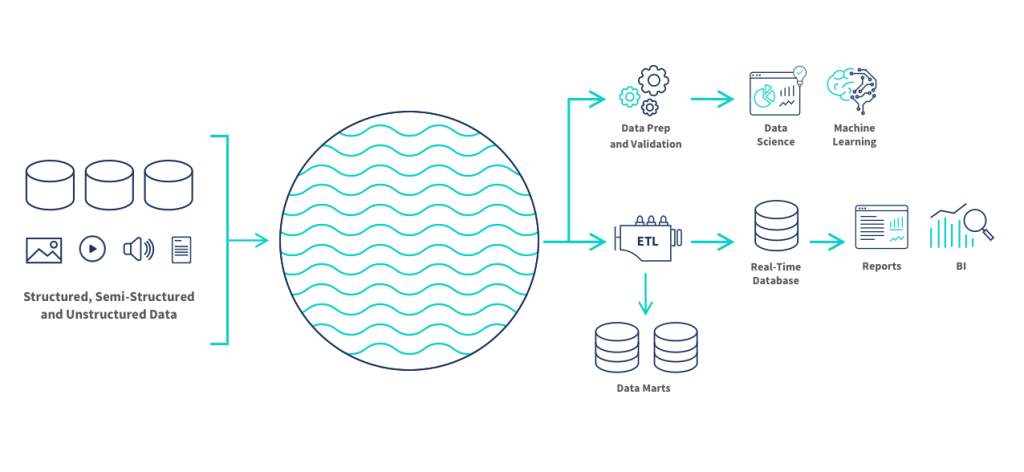
Data engineering project ini direkomendasikan bagi para pemula. Data lake merupakan subjek yang penting dalam industri data engineering sehingga kamu dapat memanfaatkan potensinya dalam meningkatkan value portofolio milikmu. Data lake merupakan suatu repository untuk menyimpan data terstruktur maupun tidak terstruktur pada berbagai skala.
Dengan mengimplementasikan project data lake, kamu dapat menambahkan beberapa jenis file di dalam repository. Tidak hanya itu, kamu juga berpeluang menginput beberapa jenis fungsi data secara cepat. Hal tersebut menjadi alasan untuk membangun project data lake kemudian mempelajarinya secara optimal. Kamu dapat mengerjakan project ini memakai Apache Spark pada AWS Cloud. Jalankan fungsi dari ETL agar dapat mentransfer data secara lebih baik dengan hasil data yang jauh lebih menarik.
- Membangun Data Warehouse
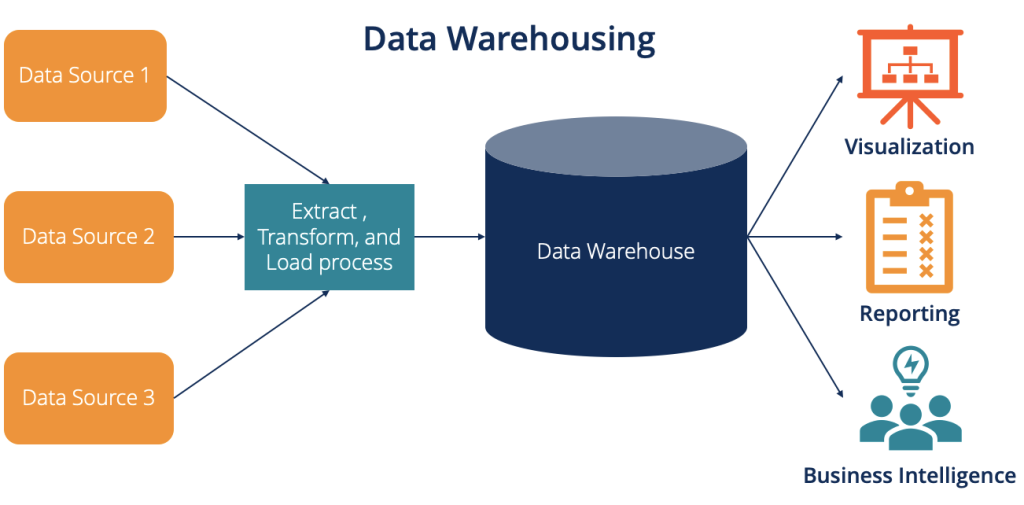
Salah satu ide terbaik untuk bereksperimen dengan project data engineering secara langsung adalah membuat data warehouse. Keterampilan ini cenderung populer di kalangan Data Engineer. Sebuah data warehouse mengumpulkan data dari sumber-sumber yang bersifat heterogen kemudian mengubahnya menjadi format standar.
Data warehousing menjadi komponen penting dalam bidang Business Intelligence (BI) dan membantu penggunaan data secara strategis. Kamu dapat merancang dan melaksanakan project ini dengan bantuan dari cloud AWS kemudian menambahkan ETL pipeline. Tujuannya untuk mentransfer kemudian mengubah data ketika masuk ke dalam warehouse.
- Forecasting
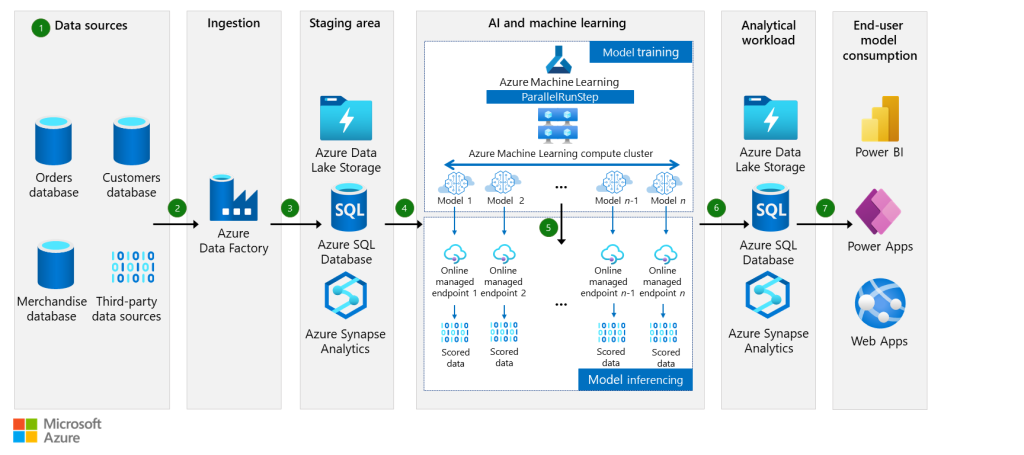
Ide project ini menggunakan historical demand data untuk memperkirakan permintaan pemasaran dalam aspek pelanggan, produk, serta tujuan di masa depan. Studi kasus diambil dari perusahaan logistik yang ingin memprediksi jumlah produk berbeda untuk dikirimkan menuju pelanggan di berbagai lokasi di masa mendatang. Perusahaan dapat memanfaatkan demand forecasts sebagai input bagi allocation tool. Allocation tool bertugas mengoptimalkan operasi rute kendaraan hingga kapasitas perencanaan secara jangka panjang.
Beberapa big data stack yang digunakan untuk project data engineering ini, antara lain:
- Azure SQL Database untuk penyimpanan data dan forecasts secara persisten
- Machine Learning web sebagai hosting dari forecasting code
- Blob Storage yang berada di tingkat menengah untuk menghasilkan prediksi sesuai kebutuhan
- Data Factory untuk mengatur proses reguler dari Azure Machine Learning Model
- Power BI dashboard untuk menampilkan dan menelusuri prediksi
- Smart IoT Infrastructure
Melalui project IoT ini, kamu akan membangun infrastruktur data yang cerdas dengan pipeline fiktif bernama Smart PipeNet. project ini mensimulasikan jaringan sensor yang terhubung ke sistem kontrol back-office. Tujuannya adalah untuk memantau aliran pipeline, memberikan feedback secara real-time, sekaligus meminimalkan potensi kerugian operasional.
- BitCoin Mining
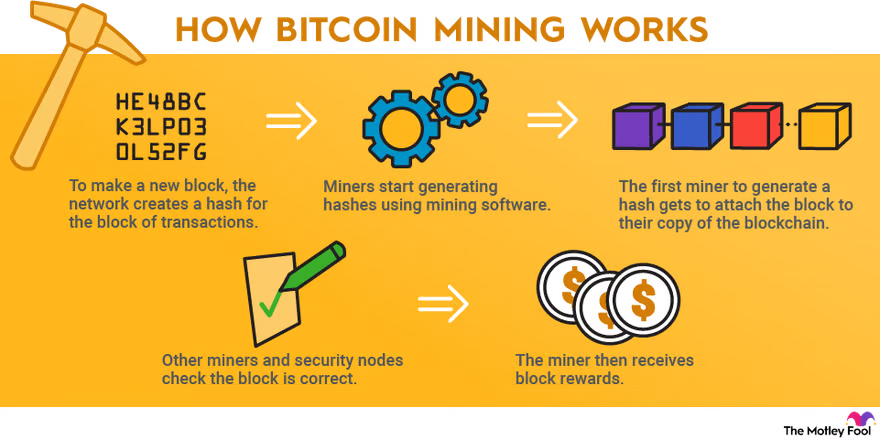
Bitcoin mining merupakan salah satu komponen terpenting dalam memelihara sekaligus mengembangkan blockchain ledger. Proses ini tidak hanya menghasilkan bitcoin baru yang masuk ke peredaran, tetapi juga menjaga keberlangsungan sistem blockchain itu sendiri. Dalam project ini, kamu akan membangun solusi berbasis komputasi matematika yang kompleks dengan memanfaatkan data publik yang tersedia secara bebas. Alurnya dirancang sebagai berikut:
- Ekstraksi Data
- Penyimpanan di HDFS
- Analisis dengan PySpark
- Penyusunan Tabel Eksternal
- Visualisasi Data
- Data Ingestion Menggunakan Google Cloud Dataflow

Project ini berfokus pada data ingestion dan alur pemrosesan yang memanfaatkan layanan Google Cloud, baik untuk real-time streaming maupun batch loads. Dataset yang digunakan adalah Yelp dataset, yang umumnya dipakai dalam penelitian maupun pembelajaran akademik. Alur pengerjaan project dapat dilakukan sebagai berikut:
- Persiapan Lingkungan
- Integrasi Tools
- Ingest Dataset
- Proses Data
- Visualisasi
BACA JUGA: Interview Data Engineer: Pertanyaan Teknis dan Non-Teknis
Bagaimana Cara Membuat Portofolio Data Engineering Project?

Memiliki project portofolio saja tidak cukup. Cara kamu menyusun, mendokumentasikan, dan menampilkan hasil pekerjaan juga sangat menentukan kesan yang akan diterima perekrut. Berikut beberapa tips yang bisa kamu terapkan:
- Gunakan Repository Github yang Terstruktur
Simpan project di GitHub atau GitLab dengan struktur folder yang rapi. Tambahkan file README.md berisi deskripsi project, alur data, teknologi yang dipakai, dan cara menjalankannya. Ini akan memudahkan perekrut memahami kontribusimu tanpa harus membuka seluruh kode.
- Dokumentasikan Alur Project dengan Jelas
angan hanya menyimpan kode. Sertakan diagram arsitektur pipeline, contoh dataset, serta penjelasan singkat mengenai tantangan yang kamu temui dan solusimu. Dokumentasi yang baik akan menunjukkan kemampuan komunikasi teknis.
- Fokus pada Relevansi Project
Pilih project yang relevan dengan kebutuhan industri, seperti pipeline ETL, real-time streaming, atau data warehouse. Lebih baik punya 3–4 project relevan daripada 10 project random yang tidak menunjukkan keterampilan inti data engineering.
- Tampilkan Hasil yang Bisa Dipahami
Selain kode, tampilkan output yang bisa langsung dipahami, seperti dashboard interaktif, laporan analitik, atau visualisasi data. Hal ini menunjukkan kamu tidak hanya fokus pada backend, tetapi juga mampu menghadirkan hasil yang bernilai bisnis.
- Manfaatkan Cloud
Jika memungkinkan, deploy project-mu di cloud seperti AWS, GCP, atau Azure. Ini akan memberi nilai tambah karena banyak perusahaan menggunakan layanan cloud dalam infrastruktur data mereka.
BACA JUGA: Data Warehouse adalah Sistem Penting Bagi Data Engineer
Kesimpulan

Membangun portofolio data engineering project bukan hanya sekadar latihan, tetapi juga investasi penting untuk kariermu. Melalui portofolio, kamu bisa membuktikan keterampilan teknis secara nyata, menunjukkan kemampuan problem-solving, sekaligus memberikan gambaran profesional tentang dirimu di mata perekrut. Project yang kamu kerjakan mulai dari data pipeline sederhana, data warehouse, hingga real-time streaming akan menjadi bukti konkret bahwa kamu mampu menghadapi tantangan dunia kerja yang sebenarnya.
Lebih dari itu, portofolio juga berfungsi sebagai media belajar berkelanjutan. Setiap project yang kamu selesaikan akan memperkaya pemahaman, melatih penggunaan tools industri, dan meningkatkan kepercayaan diri saat melamar pekerjaan. Dengan memilih project yang relevan, mendokumentasikannya dengan baik, serta memanfaatkan platform cloud, portofolio yang kamu bangun akan menjadi amunisi terbaik untuk menonjol di tengah persaingan karier data engineer.
Rekomendasi Kursus Data Engineer Terbaik
Untuk membangun portofolio data engineering project yang kuat, kamu bisa langsung berlatih lewat Bootcamp Data Engineer Digital Skola. Di kelas ini, kamu akan fokus mengerjakan project nyata dengan bimbingan mentor expert menggunakan top tools Data Engineer seperti:
- Snowflake
- Airflow
- Spark, dll
Kurikulumnya disusun agar bisa diikuti oleh siapapun, bahkan jika kamu belum memiliki latar belakang IT atau data. Setiap peserta akan dibimbing menyelesaikan project yang relevan dengan kebutuhan industri, sehingga hasilnya bisa langsung dijadikan portofolio profesional untuk menarik perhatian perekrut.
FAQ
1. Apakah pemula tanpa background IT bisa membuat portofolio data engineering?
Bisa. Banyak project dasar seperti ETL sederhana atau data modeling yang dapat dikerjakan meski tanpa latar belakang IT.
2. Tools apa yang umum dipakai dalam project data engineering?
Beberapa tools populer antara lain Python, SQL, Apache Spark, Airflow, Snowflake, serta layanan cloud seperti AWS, GCP, dan Azure.